Présentation de Nautile-370M : un modèle de raisonnement de 371M paramètres bâti sur une nouvelle architecture
Entraîné sur une fraction du volume de données habituel, Nautile-370M domine sa catégorie sur sept des onze benchmarks de raisonnement. Voici ce qu'il y a sous le capot.
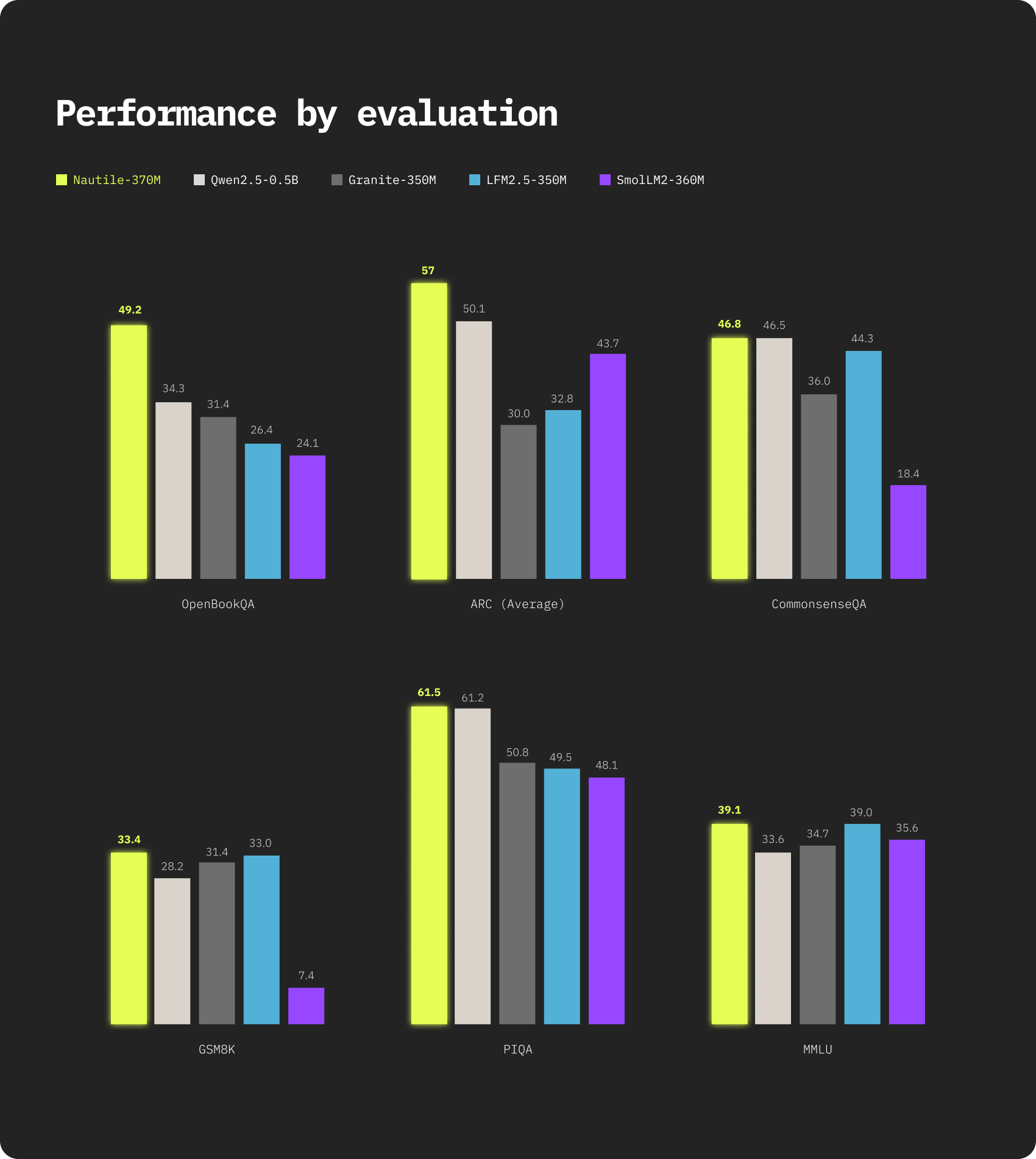
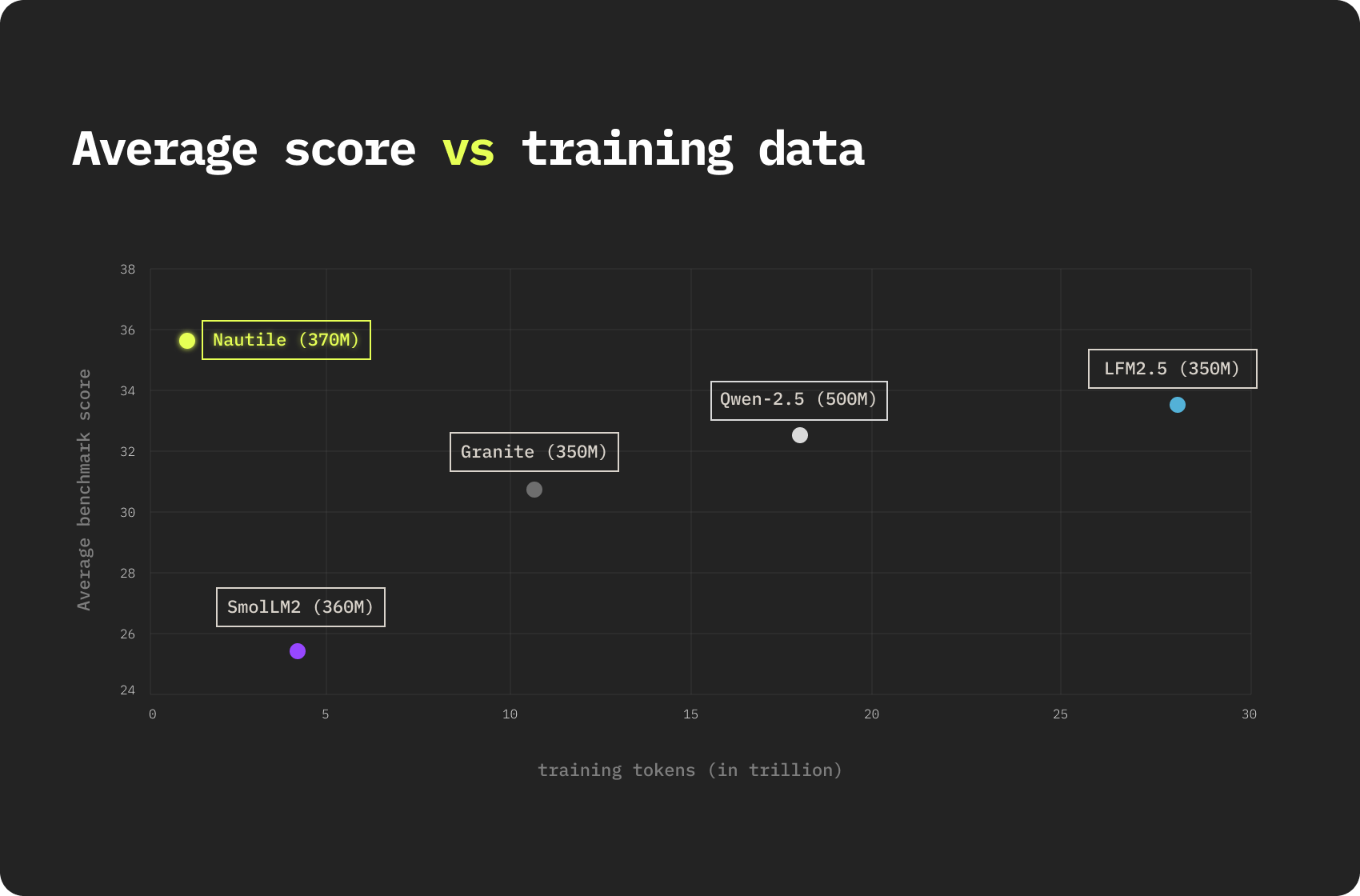
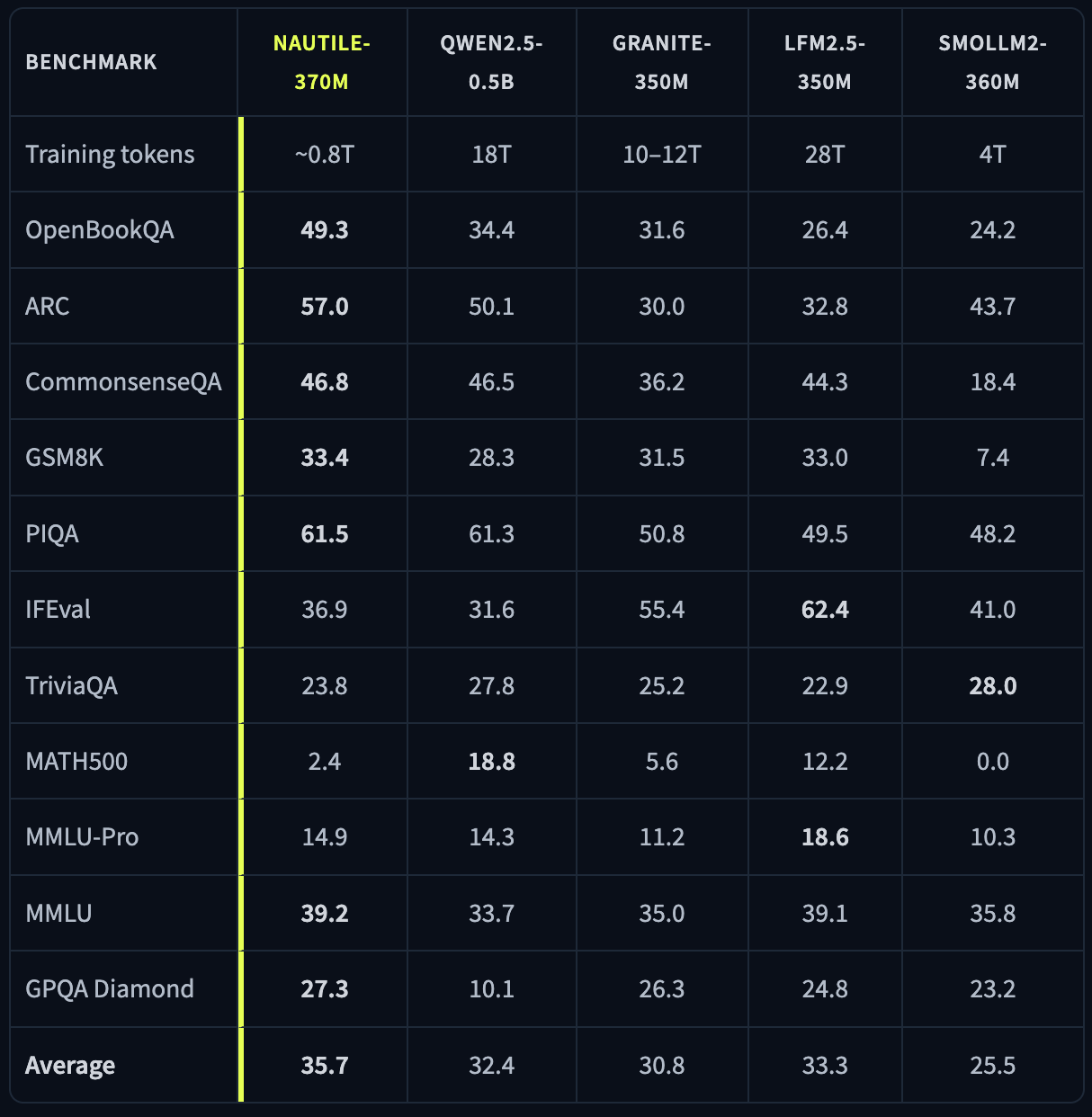
Aujourd'hui, nous publions Nautile-370M, un modèle de langage de 371M paramètres conçu pour le raisonnement sous fortes contraintes de paramètres et de compute. Il a été entraîné sur environ 0,8T tokens, une fraction de ce qui se pratique habituellement à cette échelle. SmolLM2-360M en a utilisé 4T, Granite-350M entre 10 et 12T, Qwen2.5-0.5B 18T, et LFM2.5-350M 28T. Sur onze benchmarks de raisonnement et de connaissance, Nautile-370M obtient en moyenne 35,7% et se classe premier sur sept d'entre eux.
La publication est ouverte. Le papier est sur arXiv, les poids sont sur Hugging Face. Ce post explique ce qu'est Nautile-370M, ce qui le rend différent et à quoi nous pensons qu'il est utile.
Pourquoi nous l'avons construit
Chez Trickstr, nous travaillons sur la data intelligence : analyse de réputation, veille média, suivi des parties prenantes, simulations d'opinion. La plupart de ces tâches consistent à lire de grands volumes de texte et à produire des jugements structurés, pas à générer de la prose longue. Elles tirent profit de modèles fiables, rapides et économiques à exécuter, y compris à l'échelle industrielle.
La plupart des petits modèles de cette catégorie sont optimisés en priorité pour le suivi d'instructions, l'usage d'outils ou l'assistance généraliste. Il nous fallait quelque chose calibré pour le raisonnement et la compréhension structurée à l'échelle, avec la fiabilité qu'exigent les pipelines avals de classification et d'extraction. Construire Nautile à partir de zéro nous a permis de façonner à la fois l'architecture et le mix d'entraînement autour de cet objectif précis.
Le construire de zéro était aussi l'occasion de tester une hypothèse : à l'échelle des 350M paramètres, l'architecture compte davantage que le volume brut de tokens. L'efficience en données que nous rapportons ici en est la réponse empirique.What stands out
Efficience en consommation de données
Nautile-370M a été entraîné sur environ 0,8T tokens, en deux étapes : 350B tokens de FineWeb-Edu pour la connaissance large, et 250B tokens de SYNTH pour le raisonnement explicite en chain-of-thought, plus quelques millions de documents synthétiques de suivi d'instructions. C'est 5 à 35 fois moins de données d'entraînement que tout modèle comparable, et pourtant Nautile-370M domine sur sept des onze benchmarks de sa catégorie. À nombre de paramètres égal, l'écart suggère que ce que le modèle apprend est davantage façonné par la structure de l'architecture et la curation des données que par le simple volume de tokens.
Une nouvelle architecture
Le modèle utilise la SeqCond Attention (SCA), une couche mémoire en temps linéaire dérivée du gradient de la fonction caractéristique du préfixe. Nous démontrons formellement que la lecture de la SCA est au moins aussi expressive que la self-attention complète à la limite continue, et strictement plus générale à certains égards. Le backbone alterne deux couches SCA avec une couche transformer, dans une pile de 24 couches. Les couches transformer restent en place pour gérer le petit ensemble de tâches où le routage exact entre paires est inévitable ; la SCA s'occupe du reste.
Une empreinte d'entraînement réduite
Le pré-entraînement et le fine-tuning supervisé ont tourné sur un seul pod Google Cloud TPU v4-64, alloué via le programme TPU Research Cloud. L'étape de post-training par apprentissage par renforcement a tourné sur un seul NVIDIA DGX Spark. Des petits modèles compétitifs peuvent être construits par de petites équipes.
À l'intérieur de la SCA
L'attention standard est conceptuellement simple, mais coûteuse. À chaque étape, elle compare le token courant à tous les précédents, calcule des poids et produit une moyenne pondérée. Cela donne du O(n²) en longueur de séquence, et il faut stocker en mémoire chaque clé et chaque valeur passées.
La SCA emprunte une autre voie. Au lieu de stocker une liste de tokens passés, elle maintient un résumé mathématique compact du préfixe, un état à valeurs complexes mis à jour de manière additive à mesure que de nouveaux tokens arrivent. Quand le modèle a besoin de récupérer une information, il interroge ce résumé via un produit scalaire hermitien contre une requête spectrale apprise.
Deux analogies peuvent aider. La première : plutôt que de relire un livre depuis la première page chaque fois que vous voulez vous remémorer un passage, vous gardez en tête un ensemble structuré de notes et vous les consultez. La seconde : plutôt que de sonder chaque électeur à chaque élection, vous maintenez une statistique suffisante qui capte tout ce que vous pourriez avoir besoin de savoir sur la population.
Les mathématiques derrière tout cela reposent sur la fonction caractéristique, un objet fondamental en théorie des probabilités. La fonction caractéristique d'une distribution est sa transformée de Fourier, et elle détermine la distribution de manière unique. La SCA encode le préfixe comme une distribution discrète et opère sur le gradient de sa fonction caractéristique empirique. Cela peut paraître lourd, mais les conséquences pratiques sont simples : la couche est linéaire en longueur de séquence, ses mises à jour à l'inférence se font en temps constant, et nous pouvons prouver qu'elle ne perd rien par rapport à l'attention standard à la limite continue.
Nous combinons la SCA avec un petit nombre de couches transformer standard, dans un ratio 2:1. Les couches transformer jouent le rôle de routeurs exacts entre paires quand le résumé compressé de la SCA ne suffit pas, en particulier pour les tâches qui exigent une comparaison token-à-token précise comme la copie exacte ou l'alignement symbolique.
En quoi Nautile-370M est utile ?
Nautile-370M est construit pour la compréhension, pas pour la conversation. Nous le voyons comme un cheval de trait pour les pipelines d'analyse :
- Analyse de sentiment. Notation de polarité par document à haut débit.
- Classification de sujets. Mise en correspondance d'un texte non structuré avec une taxonomie, avec une cohérence fiable.
- Détection d'intention. Inférer ce que veut un utilisateur à partir de requêtes courtes.
- Extraction d'informations structurées. Extraire entités, dates, affirmations ou autres champs structurés à partir de texte brut, à l'échelle.
- Modélisation d'opinion à grande échelle. En instanciant des milliers de personas distincts via un conditionnement léger, le modèle peut produire des réponses d'opinion à l'échelle d'un sondage sur du matériel modeste. C'est l'un des cas d'usage dans lesquels nous sommes le plus investis : les populations synthétiques permettent de simuler les réactions du public, les réponses des parties prenantes et la réception médiatique, ce qui s'applique directement au travail que nous faisons chez Trickstr.
Le fil rouge, c'est que ces tâches récompensent la compréhension précise davantage que la génération fluide. Elles passent à l'échelle de manière linéaire avec le volume d'entrée, tournent souvent dans des pipelines en batch ou en quasi-temps réel, et tirent énormément profit d'un petit modèle de raisonnement rapide.
À quoi il ne sert pas
Nous sommes tout aussi explicites sur les limites.
Nautile-370M n'est pas un modèle de chat. Une conversation multi-tours cohérente, un persona constant et une flexibilité stylistique exigent, selon notre estimation, plusieurs milliards de paramètres au minimum.
Ce n'est pas un modèle de code. Nous avons délibérément exclu les datasets de code, les benchmarks de code et les objectifs de complétion de code de toutes les étapes d'entraînement. À 371M paramètres, dépenser de la capacité sur le code diluerait le budget de représentation disponible pour le langage et le raisonnement. Du code peut apparaître de manière incidente dans le corpus de pré-entraînement, mais aucune capacité ne lui est allouée.
Comment nous l'avons entraîné
Un mot sur la façon dont tout cela a été construit, parce que la nature frugale du run fait partie de ce qui rend le résultat intéressant.
Le pré-entraînement et le fine-tuning supervisé ont tourné pendant trente jours sur un seul pod TPU v4-64 via le programme TPU Research Cloud de Google, qui accorde un accès gratuit temporaire à des ressources Cloud TPU. (merci google RCP). Le stack d'entraînement est basé sur JAX et a été conçu dès le départ pour tenir dans cette enveloppe.
L'étape d'apprentissage par renforcement nous a appris quelque chose d'inattendu. Le GRPO standard, devenu la méthode RL par défaut pour les modèles de raisonnement, n'a pas bien fonctionné sur Nautile-370M tel quel. Avec un taux de succès de référence de 28% sur GSM8K, environ trois quarts des complétions échantillonnées recevaient des avantages négatifs, et le terme de montée de gradient supprimant les traces incorrectes écrasait systématiquement le terme de descente de gradient renforçant les traces correctes. Résultat : GRPO dégradait le comportement de raisonnement que nous cherchions justement à renforcer.
Nous avons diagnostiqué le problème et proposé deux remèdes : une variante de GRPO à gradient équilibré qui redimensionne le gradient à avantage négatif pour qu'il ne domine jamais le positif, et une étape d'auto-distillation on-policy notée où le modèle est fine-tuné sur ses propres traces correctes vérifiées, avec un gradient pondéré par l'avantage non normalisé de chaque trace. Ensemble, ces ajustements ont fait passer la précision sur GSM8K de 28,0% à 33,4% sur un seul DGX Spark. Le pipeline complet est détaillé dans le papier.
Nous partageons ces difficultés parce qu'elles sont utiles à d'autres praticiens des petits modèles, et parce que nous soupçonnons que ce mode d'échec de GRPO n'est pas spécifique à nous.
Aller plus loin
Nautile-370M est la première itération d'une architecture et d'un pipeline d'entraînement que nous comptons continuer à développer. Des poids ouverts, un papier ouvert et un ensemble clair de choix de conception : voilà le point de départ.
Le modèle est ouvert et libre d'usage. Aller plus loin, c'est là que Trickstr intervient : fine-tuner les modèles sur des données propriétaires, construire des pipelines de production par-dessus, déployer des variantes spécialisées pour des industries et des problématiques précises.
Nous sommes particulièrement intéressés par des partenariats avec des organisations dont les enjeux s'alignent avec les directions que nous explorons :
- Communication stratégique. Équipes de communication corporate, directions des affaires publiques et parties prenantes institutionnelles qui ont besoin de comprendre comment leurs messages circulent, comment ils sont reçus et comment ils se reconfigurent dans le temps. Nautile est bien adapté pour cartographier la diffusion des messages, détecter les dérives narratives et quantifier les effets de cadrage sur de très grands corpus.
- Intelligence narrative et stakeholder intelligence. Identifier les acteurs qui façonnent un discours, les récits qu'ils portent et la manière dont ces récits évoluent, s'affrontent et se consolident. C'est le cœur de l'analyse de réputation moderne et le centre de ce que nous construisons déjà chez Trickstr.
- Sondages synthétiques et modélisation d'opinion. Simuler de larges populations de personas distincts pour estimer les réactions du public, anticiper les réponses des parties prenantes et tester en amont les stratégies de communication avant déploiement. Fait à l'échelle, cela devient un instrument de recherche d'un nouveau genre : moins cher, plus rapide et plus granulaire que les sondages traditionnels, et un complément naturel à ceux-ci.
- Pipelines d'extraction sectoriels. Veille réglementaire, analyse ESG et greenwashing, intelligence concurrentielle, parsing des publications financières. Partout où des jugements structurés doivent être produits à partir de grands volumes de texte avec fiabilité et traçabilité.
- Applications secteur public et recherche. Recherche en politiques publiques, analyse des débats parlementaires, veille média multilingue à travers plusieurs juridictions. Nous avons déjà déployé des pipelines comparables dans cet espace et sommes désireux de les étendre avec des partenaires apportant une profondeur sectorielle et des données propriétaires.
Si l'un de ces axes correspond à votre roadmap, nous serons ravis d'en discuter. Les partenariats les plus productifs que nous avons construits combinent trois choses : un problème opérationnel clair, des données propriétaires qu'un modèle générique ne peut pas atteindre, et une volonté d'investir dans une solution ciblée et durable plutôt que dans un correctif rapide.
Remerciements
Nautile-370M n'existerait pas sans le programme TPU Research Cloud de Google. Le TRC accorde un accès gratuit à des ressources Cloud TPU pour les chercheurs, sans contrepartie. Pour une petite équipe sans budget compute à l'échelle d'un hyperscaler, ce type de soutien fait toute la différence entre une idée sur un tableau blanc et un modèle qui sort. L'allocation de trente jours de TPU v4-64 que nous avons reçue a couvert l'intégralité du pré-entraînement et du fine-tuning supervisé de Nautile-370M, et le stack d'entraînement JAX que nous avons construit a été conçu pour tenir dans ce cadre dès le premier jour.
Nous sommes reconnaissants à l'équipe TRC d'avoir rendu cela possible, et pour le pari plus large qu'elle continue de prendre sur la recherche indépendante. Si vous travaillez sur quelque chose limité par le compute et sous-financé, candidater au TRC est l'une des actions à plus fort effet de levier que vous puissiez entreprendre.
Liens
- Papier : https://arxiv.org/abs/2604.24809
- Poids : https://huggingface.co/trickstr-ai/nautile-370m