Introducing Nautile-370M: A 371M reasoning model built on a new architecture
Trained on a fraction of the usual data, Nautile-370M leads its class on seven of eleven reasoning benchmarks. Here's what's inside.
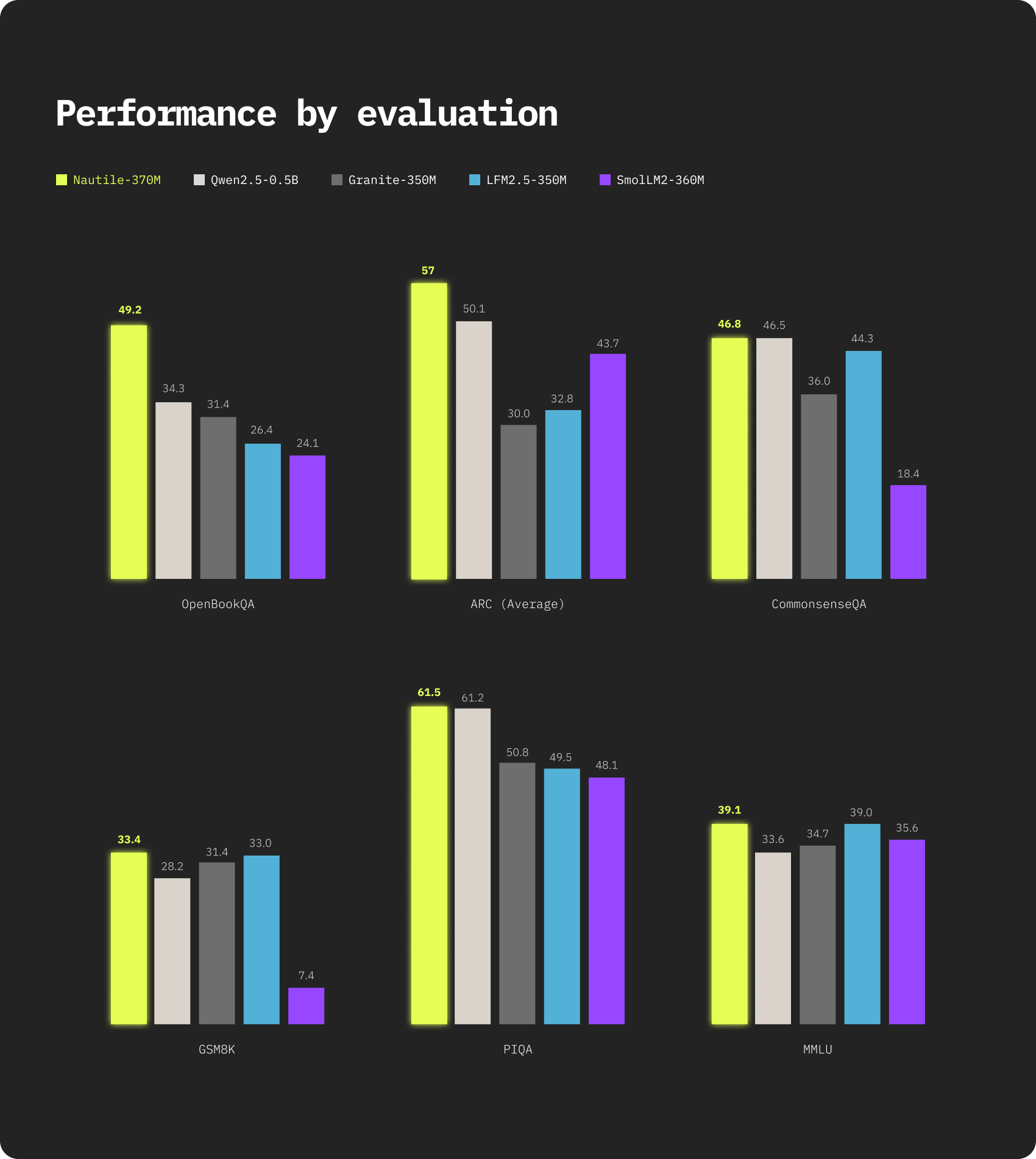
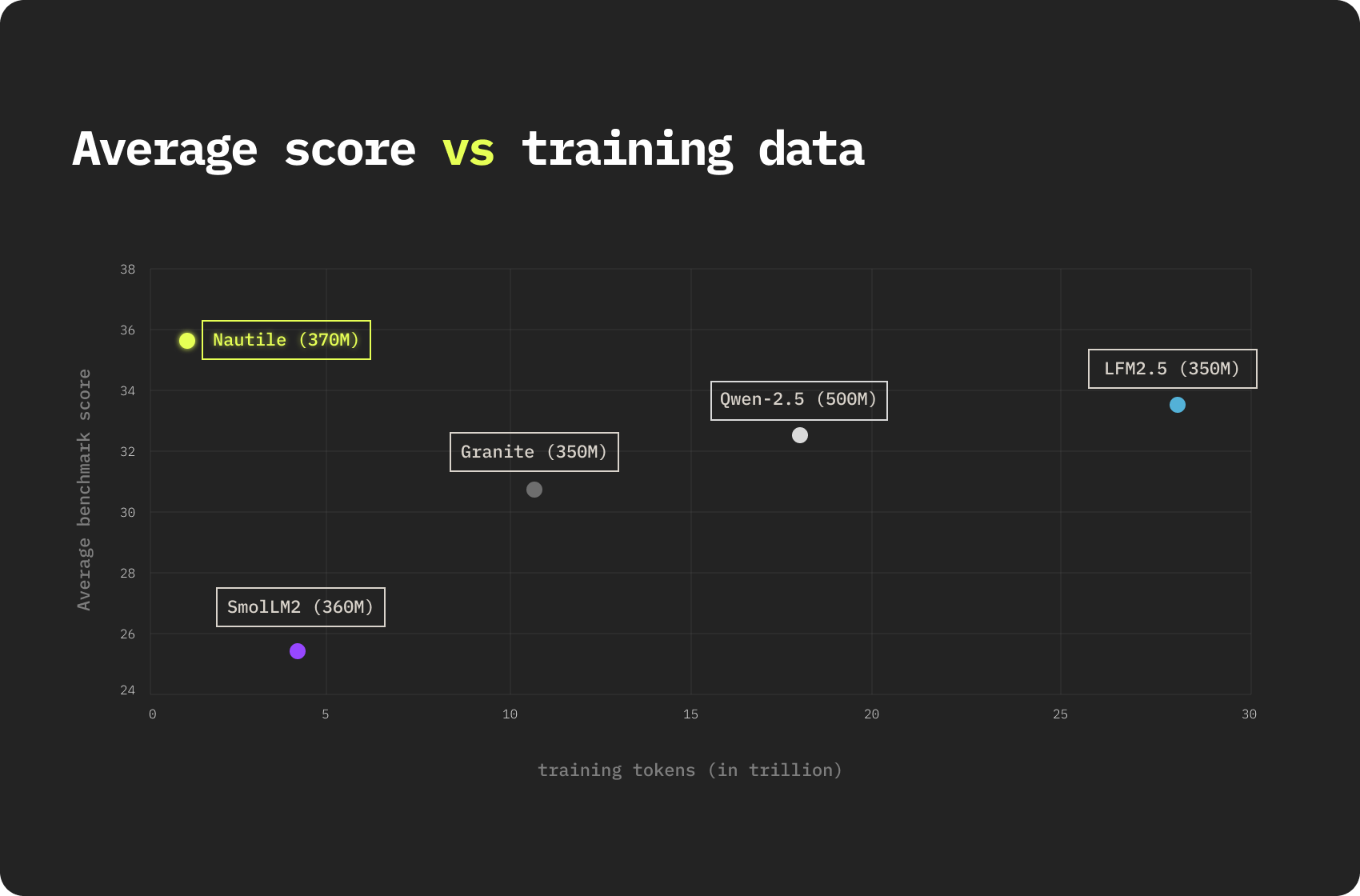
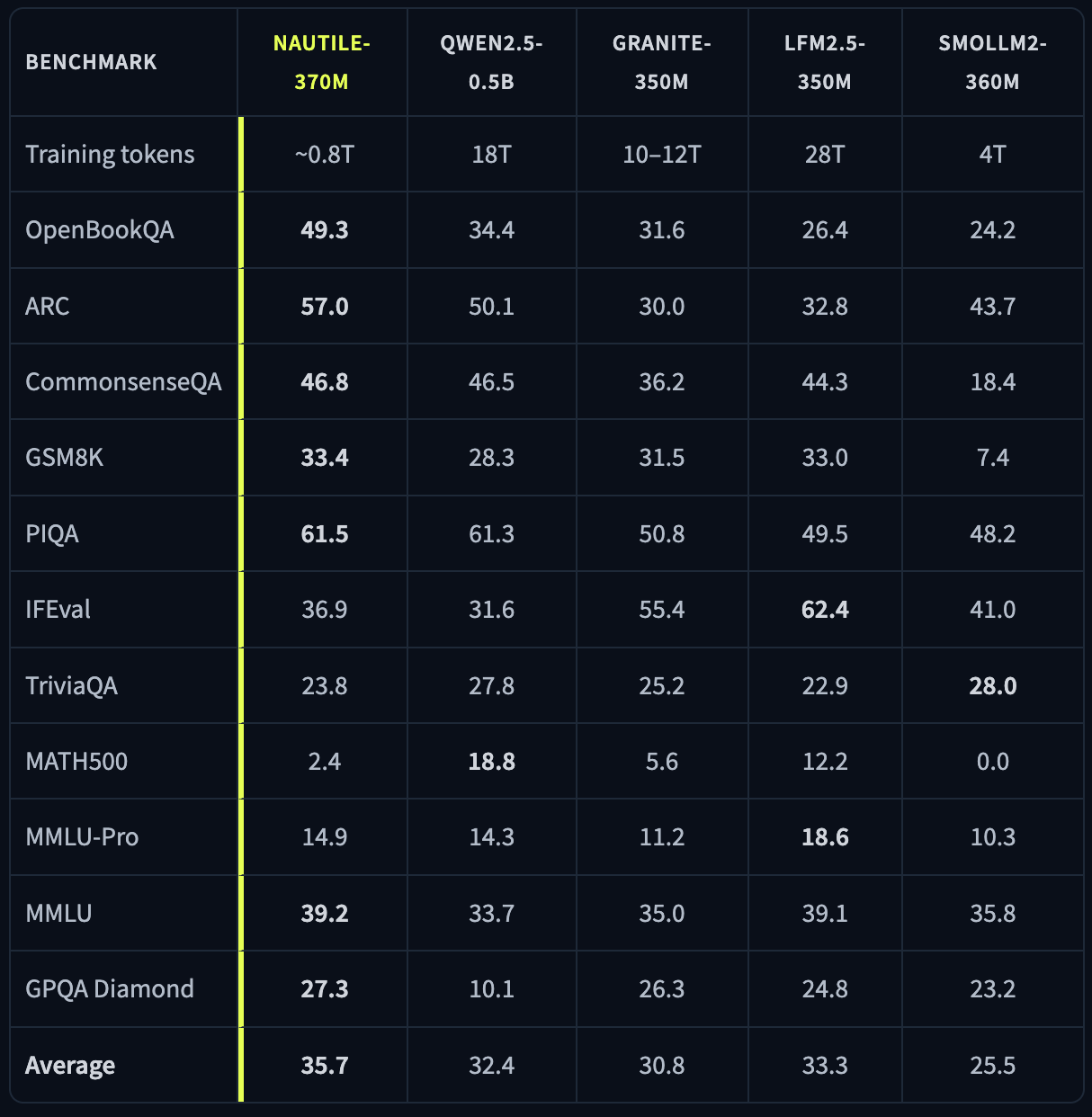
Today we are releasing Nautile-370M, a 371M parameter language model designed for reasoning under tight parameter and compute budgets. It was trained on roughly 0.8T tokens, a fraction of what is typical at this scale. SmolLM2-360M used 4T, Granite-350M used 10 to 12T, Qwen2.5-0.5B used 18T, and LFM2.5-350M used 28T. Across eleven reasoning and knowledge benchmarks, Nautile-370M scores 35.7% on average and ranks first on seven of them.
The release is open. The paper is on arXiv, the weights are on Hugging Face. This post explains what Nautile-370M is, what makes it different, and what we think it is good for.
Why we built it
At Trickstr we work on data intelligence: reputation analysis, media monitoring, stakeholder tracking, opinion simulations. Most of these tasks are about reading large volumes of text and producing structured judgments, not generating long-form prose. They benefit from models that are reliable, fast, and cheap to run, even at industrial scale.
Most small models in this class are primarily optimized for instruction following, tool use, or general-purpose assistance. We needed something tuned for reasoning and structured understanding at scale, with the reliability that downstream classification and extraction pipelines require. Building Nautile from scratch let us shape both the architecture and the training mix around that specific goal.
Building it from scratch was also an opportunity to test a hypothesis: that at the 350M parameter scale, architecture matters more than raw token count. The data efficiency we report here is the empirical answer.
What stands out
Data efficiency
Nautile-370M was trained on around 0.8T tokens, in two stages: 350B tokens of FineWeb-Edu for broad knowledge, and 250B tokens of SYNTH for explicit chain-of-thought reasoning, plus a few million synthetic instruction-following documents. That is 5 to 35 times less training data than every comparable model, and yet Nautile-370M leads on seven of eleven benchmarks in its class. Holding the parameter count constant, the gap suggests that what the model learns is more shaped by the structure of the architecture and the curation of the data than by sheer token volume.
A new architecture
The model uses SeqCond Attention (SCA), a linear-time memory layer derived from the gradient of the prefix's characteristic function. We prove formally that the SCA readout is at least as expressive as full self-attention in the continuous limit, and strictly more general in some respects. The backbone alternates two SCA layers with one transformer layer, in a 24-layer stack. The transformer layers stay in to handle the small set of tasks where exact pairwise routing is unavoidable; SCA does the rest.
Tiny training footprint
Pretraining and supervised fine-tuning ran on a single Google Cloud TPU v4-64 pod, granted via the TPU Research Cloud program. The reinforcement learning post-training stage ran on a single NVIDIA DGX Spark. Competitive small models can be built by small teams.
Inside SCA, in plain terms
Standard attention is conceptually simple but expensive. At every step, it compares the current token to every previous one, computes weights, and produces a weighted average. That is O(n²) in the sequence length, and it requires storing every past key and value in memory.
SCA takes a different route. Instead of storing a list of past tokens, it maintains a compact mathematical summary of the prefix, a complex-valued state that is updated additively as new tokens arrive. When the model needs to retrieve information, it queries this summary through a Hermitian inner product against a learned spectral query.
Two analogies might help. The first: instead of re-reading a book from page one every time you want to recall a passage, you keep a structured set of notes in your head and consult those. The second: instead of polling every voter at every election, you maintain a sufficient statistic that captures everything you might need to know about the population.
The mathematics behind this is the characteristic function, a fundamental object in probability theory. The characteristic function of a distribution is its Fourier transform, and it determines the distribution uniquely. SCA encodes the prefix as a discrete distribution and operates on the gradient of its empirical characteristic function. This sounds heavy, but the practical consequences are simple: the layer is linear in sequence length, has constant-time updates at inference, and we can prove that it loses nothing compared to standard attention in the continuous limit.
We pair SCA with a small number of standard transformer layers, in a 2:1 ratio. The transformer layers act as exact pairwise routers when SCA's compressed summary is not enough, particularly for tasks that require precise token-to-token comparison such as exact copying or symbolic alignment.
What Nautile-370M is good for
Nautile-370M is built for understanding, not for conversation. We see it as a workhorse for analysis pipelines:
- Sentiment analysis. Per-document polarity scoring at high throughput.
- Topic classification. Mapping unstructured text to a taxonomy with reliable consistency.
- Intent detection. Inferring what a user wants from short queries.
- Structured information extraction. Pulling entities, dates, claims, or other structured fields from raw text at scale.
- Large-scale opinion modeling. By instantiating thousands of distinct personas through lightweight conditioning, the model can produce survey-scale opinion responses on modest hardware. This is one of the use cases we are most invested in: synthetic populations enable simulation of public reactions, stakeholder responses, and media reception, which is directly applicable to the work we do at Trickstr.
The common thread is that these tasks reward precise understanding more than fluent generation. They scale linearly with input volume, often run in batch or near-real-time pipelines, and benefit enormously from a small, fast, reasoning model.
What it is not for
We are equally explicit about the limits.
Nautile-370M is not a chat model. Coherent multi-turn conversation, consistent persona, and stylistic flexibility require, in our estimation, several billion parameters at minimum.
It is not a code model. We deliberately excluded coding datasets, coding benchmarks, and code-completion objectives from all training stages. At 371M parameters, spending capacity on code would dilute the representation budget available for language and reasoning. Code may appear incidentally in the pretraining corpus, but no capacity is allocated to it.
The training story
A note on how this was built, because the lean nature of the run is part of what makes the result interesting.
Pretraining and supervised fine-tuning ran for thirty days on a single TPU v4-64 pod through Google's TPU Research Cloud program, which grants temporary free access to Cloud TPU resources. (thank you google RCP). The training stack is JAX-based and was designed to fit within this allocation from the start.
The reinforcement learning stage taught us something we did not expect. Standard GRPO, the now-default RL method for reasoning models, did not work well on Nautile-370M out of the box. With a 28% baseline success rate on GSM8K, roughly three quarters of sampled completions received negative advantages, and the gradient ascent term suppressing incorrect traces consistently overwhelmed the gradient descent term reinforcing correct ones. The result was that GRPO degraded the very reasoning behavior we wanted to reinforce.
We diagnosed this and proposed two mitigations: a gradient-balanced GRPO variant that rescales the negative-advantage gradient so it never dominates the positive one, and a scored on-policy self-distillation stage where the model is fine-tuned on its own verified correct traces, with the gradient weighted by the unnormalized advantage of each trace. Together, these brought GSM8K accuracy from 28.0% to 33.4% on a single DGX Spark. The full pipeline is detailed in the paper.
We share these challenges because they are useful to other small-model practitioners, and because we suspect this failure mode of GRPO is not specific to us.
Going further
Nautile-370M is the first iteration of an architecture and a training pipeline we plan to keep developing. Open weights, an open paper, and a clear set of design choices are the starting point.
The model is open and free to use. Going further is where Trickstr comes in: fine-tuning models on proprietary data, building production pipelines on top, deploying specialized variants for specific industries and problems.
We are particularly interested in partnering with organizations whose challenges align with the directions we are pushing:
- Strategic communication. Corporate communications teams, public affairs offices, and institutional stakeholders who need to understand how their messages travel, how they are received, and how they reshape over time. Nautile is well-suited to map message diffusion, detect narrative drift, and quantify framing effects across very large corpora.
- Narrative and stakeholder intelligence. Identifying the actors who shape a discourse, the narratives they carry, and the way these narratives evolve, compete, and consolidate. This is the core of modern reputation analysis and the heart of what we already build at Trickstr.
- Synthetic surveys and opinion modeling. Simulating large populations of distinct personas to estimate public reactions, anticipate stakeholder responses, and pre-test communication strategies before deployment. Done at scale, this becomes a new kind of research instrument: cheaper, faster, and more granular than traditional polling, and a natural complement to it.
- Industry-specific extraction pipelines. Regulatory monitoring, ESG and greenwashing analysis, competitive intelligence, financial disclosure parsing. Anywhere structured judgments need to be produced from large volumes of text with reliability and traceability.
- Public sector and research applications. Policy research, parliamentary debate analysis, multilingual media monitoring across jurisdictions. We have already deployed comparable pipelines in this space and are eager to extend them with partners who bring domain depth and proprietary data.
If any of these axes match your roadmap, we would welcome the conversation. The most productive partnerships we have built combine three things: a clear operational problem, proprietary data that a generic model cannot access, and a willingness to invest in a focused, durable solution rather than a quick fix.
A note of thanks
Nautile-370M would not exist without Google's TPU Research Cloud program. The TRC grants free access to Cloud TPU resources for researchers, with no strings attached. For a small team without a hyperscaler-sized compute budget, this kind of support is the difference between an idea on a whiteboard and a model that ships. The thirty-day TPU v4-64 allocation we received covered the full pretraining and supervised fine-tuning of Nautile-370M, and the JAX-based training stack we built was designed to run within it from day one.
We are grateful to the TRC team for making this possible, and for the broader bet they continue to make on independent research. If you are working on something compute-bound and underfunded, applying to TRC is one of the highest-leverage things you can do.
Links
- Paper: https://arxiv.org/abs/2604.24809
- Weights: https://huggingface.co/trickstr-ai/nautile-370m